Exploring Novel Memory Architectures Using Emerging Devices

There has long been a disconnect between the device and the architecture communities in academia, despite the need for concentrated co-design of devices and architectures to achieve viable end products. Device researchers continue to generate several new devices, as well as improved versions of existing devices, that are potential candidates for computer memories. However, it often leads to pitfalls such as designing isolated devices, which can ignore issues such as manufacturing variability, cycle-to-cycle variation, aggregated faults, and data lifetimes, among other issues. To this extend, I am currently working with Prof. Saugata Ghose at ARCANA Group, University of Illinois Urbana-Champaign to create a platform that can evaluate all of the devices comparatively and adapt easily to incorporate new devices that continue to be generated. My work will involve building a multi-level simulator (MASTODON) to study the functionality of emerging memory devices, and how these devices operate in chip-scale memory architectures. Currently, I am working on developing a parser to convert device-level Verilog-A models into high-level Python functions to extract latency and switching energy. To model the parasitic resistance and capacitance in a crossbar array and its effect on latency, I have been working on training a LSTM-based neural network to predict the different voltage input curves for memory cells at different locations.
CtrlPIM: A Microcode-based Controller for Memristive Memory Processing Unit

In the recent past, there has been a significant interest in Processing-in-Memory (PIM) – a concept where computation is performed within the memory subsystem itself, rather than transferring data back and forth between memory and a separate processing unit. PIM can offer significant performance improvements for certain types of workloads, particularly those that involve large-scale data processing or machine learning. To enable PIM, memory controllers need to be redesigned to include processing capabilities. Traditional memory controllers are designed primarily to manage data movement between memory & the processing unit, but PIM controllers need to be able to perform computation on data as it is stored in memory. Based on this idea, I worked with Prof. Shahar Kvatinsky at ASIC2 group, Technion – Israel Institute of Technology to design a comprehensive, general-purpose ISA for digital PIM architecture. This ISA allows programmers to execute a significant segment of general-purpose applications on the memristive memory processing unit (mMPU), with the ISA supporting various commonly used operations including general arithmetic and logical instructions. To enable utilisation of the proposed ISA on the mMPU, we proposed CtrlPIM, a flexible, microcode-based mMPU controller. Its microcode-based design affords the flexibility to add or modify PIM instructions to the ISA by changing the control program only, requiring no hardware modifications. Lastly, to integrate CtrlPIM with the CPU, we designed a system capable of executing programs comprising PIM instructions. The complete system design was implemented on a Xilinx Zynq-7000 System-on-Chip (SoC). A paper on this work is currently under review at IEEE Design, Automation and Test in Europe Conference (DATE) 2024.
Assessing the Performance of Stateful Logic in 1-Selector 1-RRAM Crossbar
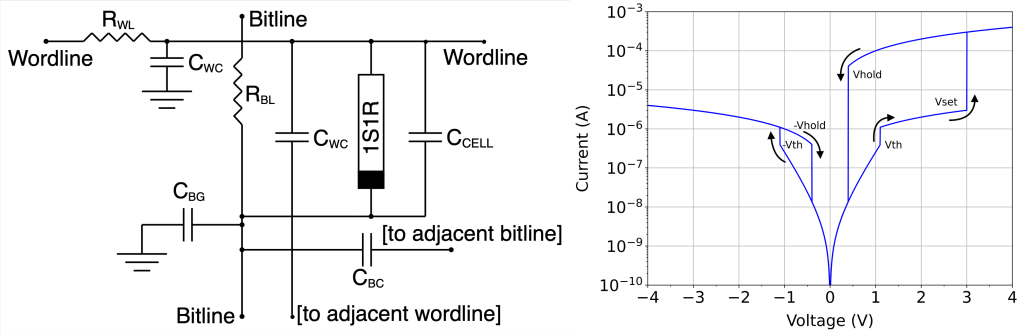
Passive RRAM or 1R crossbar array is a type of resistive random-access memory (RRAM) architecture in which memory cells are arranged in a matrix-like structure with each cell connected to a pair of orthogonal wires. The cells are passive, meaning they do not have any active components such as transistors. The significant limitation of passive RRAM crossbar arrays is sneak path current, which occurs when current flows through unintended cells, leading to errors in reading & writing data. Active RRAM or 1S1R crossbar arrays solve this limitation by incorporating a transistor or other 2-terminal nonlinear devices known as selectors into each memory cell, allowing for more precise control of current flow & preventing sneak path current. While many works designed & characterised 1S1R cells with various types of selectors, none of them explored their performance for stateful logic like Memristor-Aided Logic (MAGIC). To this extent, as my bachelor thesis, I worked with Prof. Shahar Kvatinsky on assessing the performance of stateful logic on 1S1R crossbar arrays. I designed a robust Verilog-A model for 1S1R cell and fit it to VO2-based selector and TiN/TiOx/HfOx/Pt RRAM device. Furthermore, extensive crossbar array of varying sizes are modelled including the parasitic resistances and capacitance and simulated to study MAGIC operations. Our results indicate that, on average, 1S1R crossbar array consumes 21.9x and 24.4x less power than 1R crossbar for NOR(0,0) and NOR(0,1)/NOR(1,0)/NOR(1,1) operations, respectively. Furthermore, the readout margin of 1S1R crossbar array is, on average, 4.5x more than 1R crossbar array, thereby enabling much larger crossbar array. A paper on this work is currently under preparation and to be summited at IEEE International Symposium for Circuits and Systems (ISCAS) 2024.
Hardware-Efficient Reinforcement Learning on Passive RRAM Crossbar Array
The unprecedented growth in the field of machine learning has led to the development of deep neuromorphic networks trained on labelled dataset with capability to mimic or even exceed human capabilities. However, for applications involving continuous decision making in unknown environments, such as rovers for space exploration, robots, unmanned aerial vehicles, etc., explicit supervision and generation of labelled data set is extremely difficult and expensive. Reinforcement learning (RL) allows the agents to take decisions without any (human/external) supervision or training on labelled dataset. However, the conventional implementations of RL on advanced digital CPUs/GPUs incur a significantly large power dissipation owing to their inherent von-Neumann architecture. Although cross-point arrays of emerging non-volatile memories such as resistive (R)RAMs with their innate capability to perform energy-efficient in-situ multiply-accumulate operation appear promising for Q-learning- based RL implementations, their limited endurance restricts their application in practical RL systems with overwhelming weight updates. To address this issue and realize the true potential of RRAM-based RL implementations, I worked with Prof. Shubham Sahay at NeuroCHaSe Group, Indian Institute of Technology Kanpur to perform an algorithm-hardware co-design and propose a novel implementation of Monte Carlo (MC) RL algorithm on passive RRAM crossbar array. I analysed the performance of the proposed MC RL implementation on the classical cart- pole problem and demonstrate that it not only outperforms the prior digital and active 1-Transistor-1-RRAM (1T1R)-based implementations by more than five orders of magnitude in terms of area but is also robust against the spatial and temporal variations and endurance failure of RRAMs. A paper on this work is currently under preparation and to be summited at IEEE International Symposium for Circuits and Systems (ISCAS) 2024.
